Longbow
This is another type of processor which is also applied post SQL query processing in the Dagger workflow. This feature allows users to aggregate data over long windows in real-time. For certain use-cases, you need to know the historical data for an event in a given context. Eg: For a booking event, a risk prevention system would be interested in 1 month pattern of the customer. Longbow solves the above problem, the entire historical context gets added in the same event which allows downstream systems to process data without any external dependency. In order to achieve this, we store the historical data in an external data source. After evaluating a lot of data sources we found Bigtable to be a good fit primarily because of its low scan queries latencies. This currently works only for Kafka sink.
Components
In order to make this work in a single Dagger job, we created the following components.
Longbow writer#
This component is responsible for writing the latest data to Bigtable. It uses Flink's Async IO in order to make this network call.
Workflow#
- Create a new table(if doesn't exist) with the name same as Dagger job name or using PROCESSOR_LONGBOW_GCP_PROJECT_ID.
- Receives the record post SQL query processing.
- Creates the Bigtable key by combining data from longbow_key, a delimiter, and reversing the event_timestamp. Timestamps are reversed in order to achieve lower latencies in scan query, more details here.
- Creates the request by adding all the column values from SQL as Bigtable row columns which are passed with
longbow_dataas a substring in the column name. - Makes the request.
- Passes the original record post SQL without any modifications to longbow_reader.
Note: By default we create tables with retention of 3 months in Bigtable.
Longbow reader#
This component is responsible for reading the historical data from Bigtable and forwarding it to the sink. It also uses Flink's Async IO in order to make this network call.
Workflow#
- Builds the scan request for Bigtable. We provide two configurable strategies for defining the range of the query.
- Duration range: It will scan from the latest event's timestamp to a provided duration.
- Absolute range: You can provide the absolute range by setting longbow_latest and longbow_earliest in the SQL query.
- Makes the scan request and receives the result.
- Parses the response and creates a separate list of values for every column. Thus every record post this stage will have its historical data within the same record.
- Forwards the data to the sink.
Data flow in longbow
In this example, let's assume we have booking events in a Kafka cluster and we want to get information of all the order numbers and their driver ids for customers in the last 30 days. Here customer_id will become longbow_key.
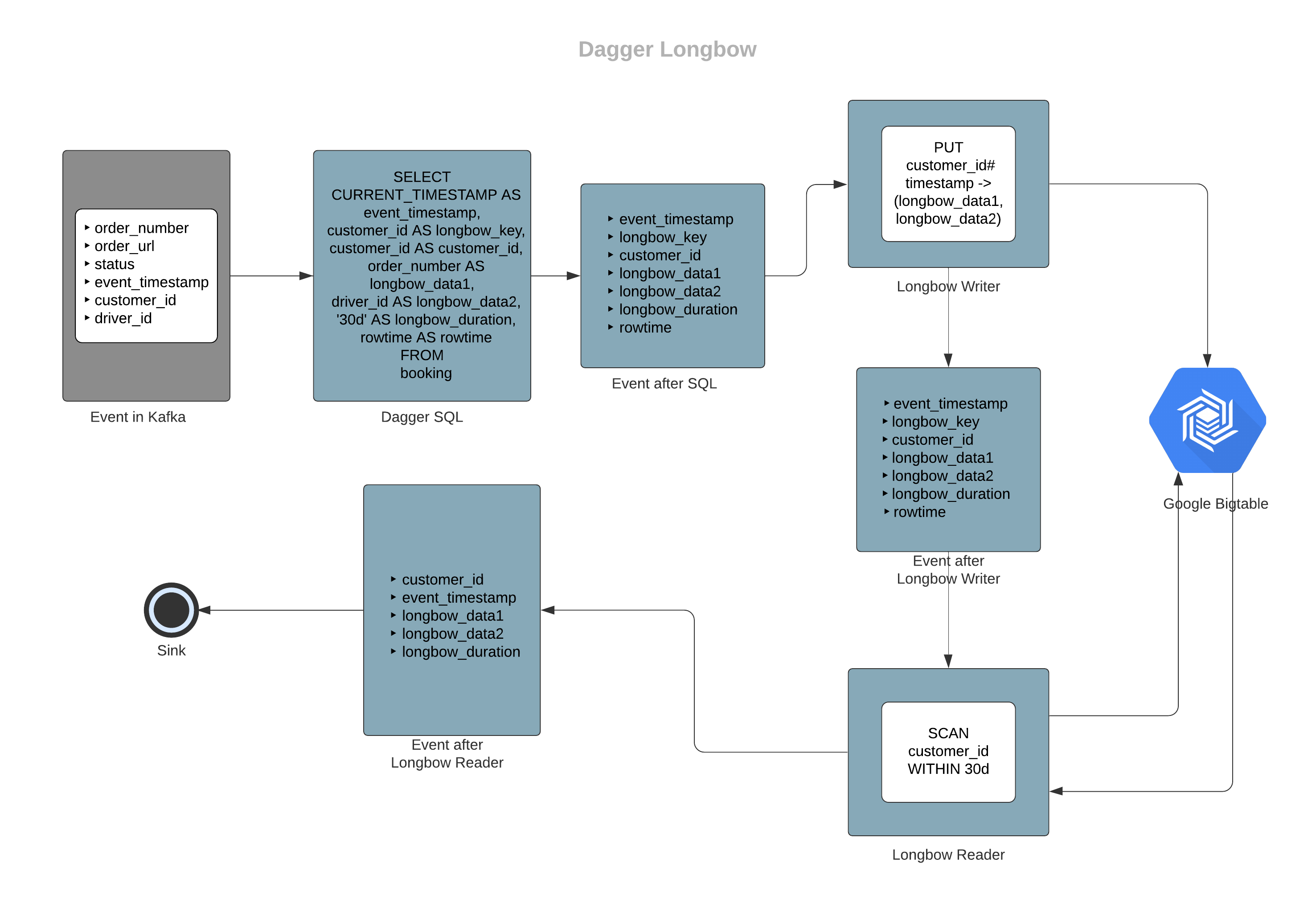
Sample input schema for booking
message SampleBookingInfo { string order_number = 1; string order_url = 2; Status.Enum status = 3; google.protobuf.Timestamp event_timestamp = 4; string customer_id = 5; string driver_id = 6;}Sample output schema for longbow output
message BookingWithHistory { string customer_id = 1; google.protobuf.Timestamp event_timestamp = 2; repeated string longbow_data1 = 3; repeated string longbow_data2 = 4; string longbow_duration = 5;}Sample Query
# here booking denotes the booking events stream with the sample input schemaSELECT CURRENT_TIMESTAMP AS event_timestamp, customer_id AS longbow_key, customer_id AS customer_id, order_number AS longbow_data1, driver_id AS longbow_data2, '30d' AS longbow_duration, rowtime AS rowtimeFROM bookingIn the above example, order_number and driver_id fields are selected as longbow_data1 and longbow_data2, so they will be considered as Bigtable row columns as explained in the longbow writer workflow above. The final output will have a list of order_numbers in the longbow_data1 field and a list of driver_id in longbow_data2.
In case you want orders from the start of the month to the end of the month, then instead of using the Duration range i.e. 30d, you can also give an absolute range, example query below.
# here booking denotes the booking events stream with the sample input schemaSELECT CURRENT_TIMESTAMP AS event_timestamp, customer_id AS longbow_key, customer_id AS customer_id, order_number AS longbow_data1, driver_id AS longbow_data2, StartOfMonth( TimestampFromUnix(event_timestamp.seconds), 'Asia/Jakarta' ) as longbow_earliest, EndOfMonth( TimestampFromUnix(event_timestamp.seconds), 'Asia/Jakarta' ) as longbow_latest, rowtime AS rowtimeFROM bookingHere, StartOfMonth, EndOfMonth and TimestampFromUnix are custom UDFs.
Configurations
Longbow is entirely driven via SQL query, i.e. on the basis of presence of certain columns we identify longbow parameters. Following configs should be passed via SQL query as shown in the above example.
longbow_key#
The key from the input which should be used to create the row key for Bigtable. Longbow will be enabled only if this column is present.
- Example value:
customer_id - Type:
required
longbow_duration#
The duration for the scan query. It can be passed in minutes(m), hours(h) and days(d).
- Example value:
30d - Type:
optional
longbow_latest#
The latest/recent value for the range of scan. This needs to be set only in case of absolute range. You can also use custom UDFs to generate this value as shown in the above example.
- Example value:
1625097599 - Type:
optional
longbow_earliest#
The earliest/oldest value for the range of scan. This needs to be set only in case of absolute range. You can also use custom UDFs to generate this value as shown in the above example.
- Example value:
1622505600 - Type:
optional
event_timestamp#
The timestamp to be used to build the Bigtable row keys.
- Example value:
CURRENT_TIMESTAMP - Type:
required
rowtime#
The time attribute column. Read more here.
- Example value:
rowtime - Type:
required
For additional global configs regarding longbow, please refer here.